Samsung Research
AI Researcher, 2D/3D Computer Vision
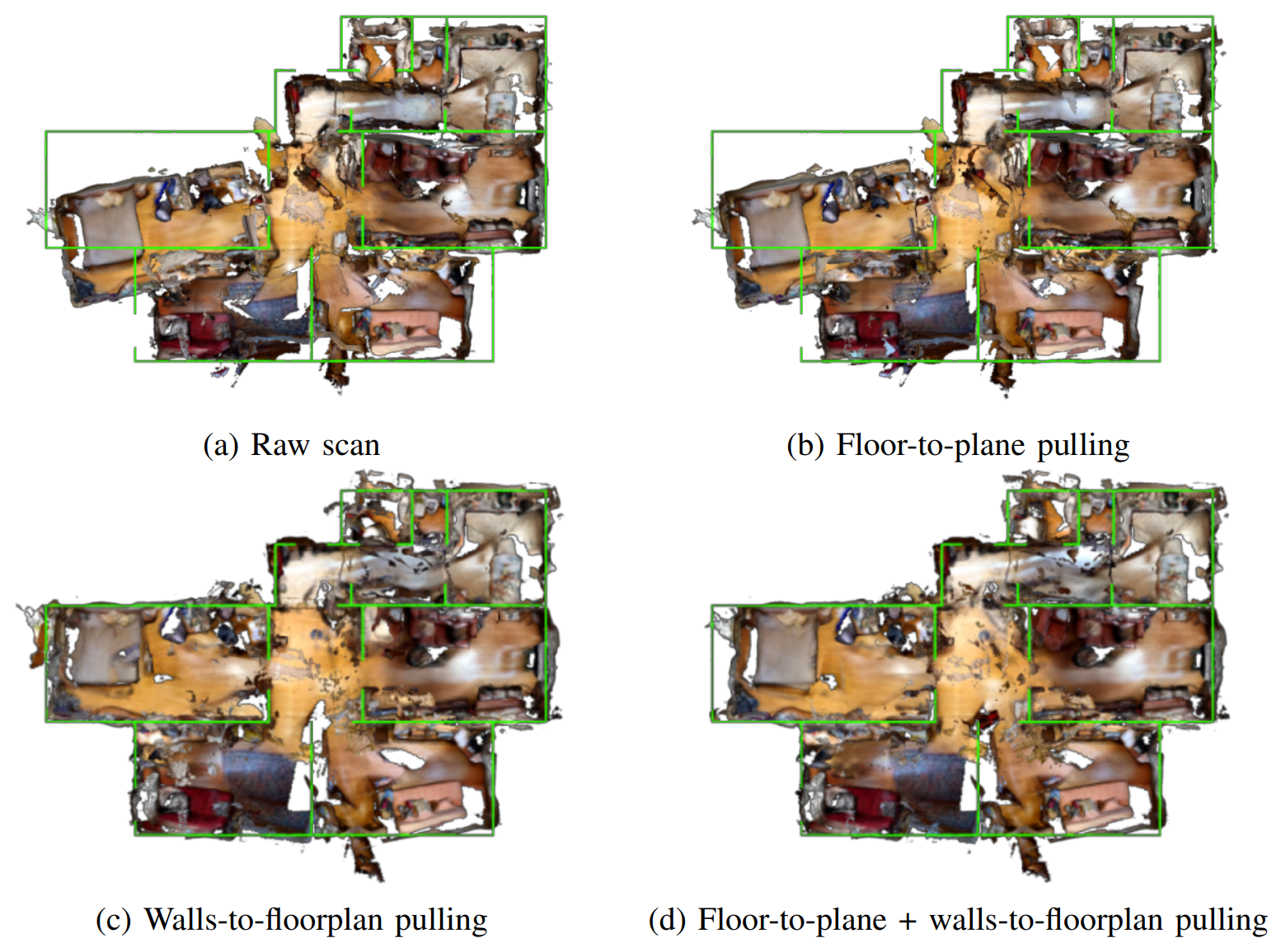
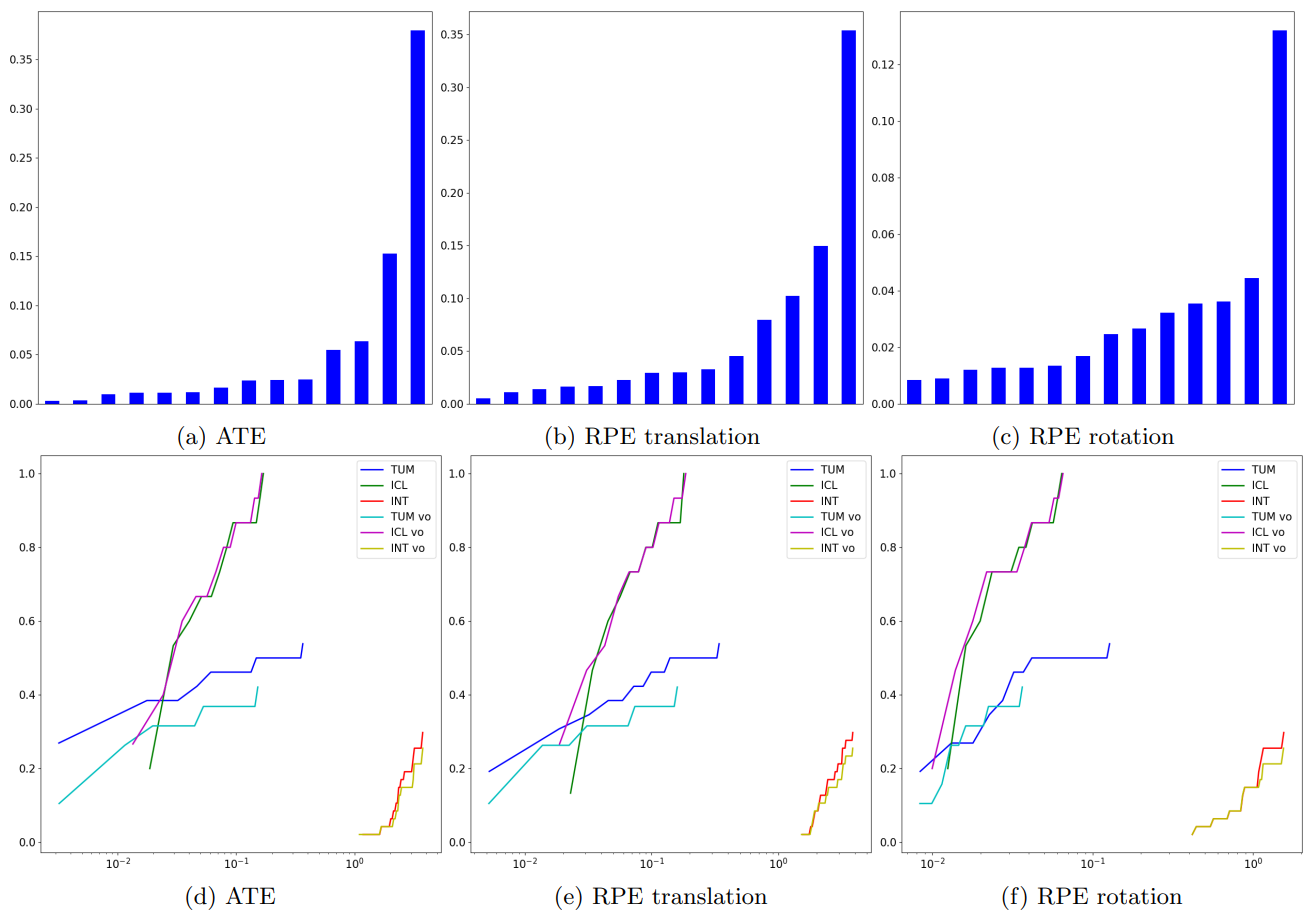
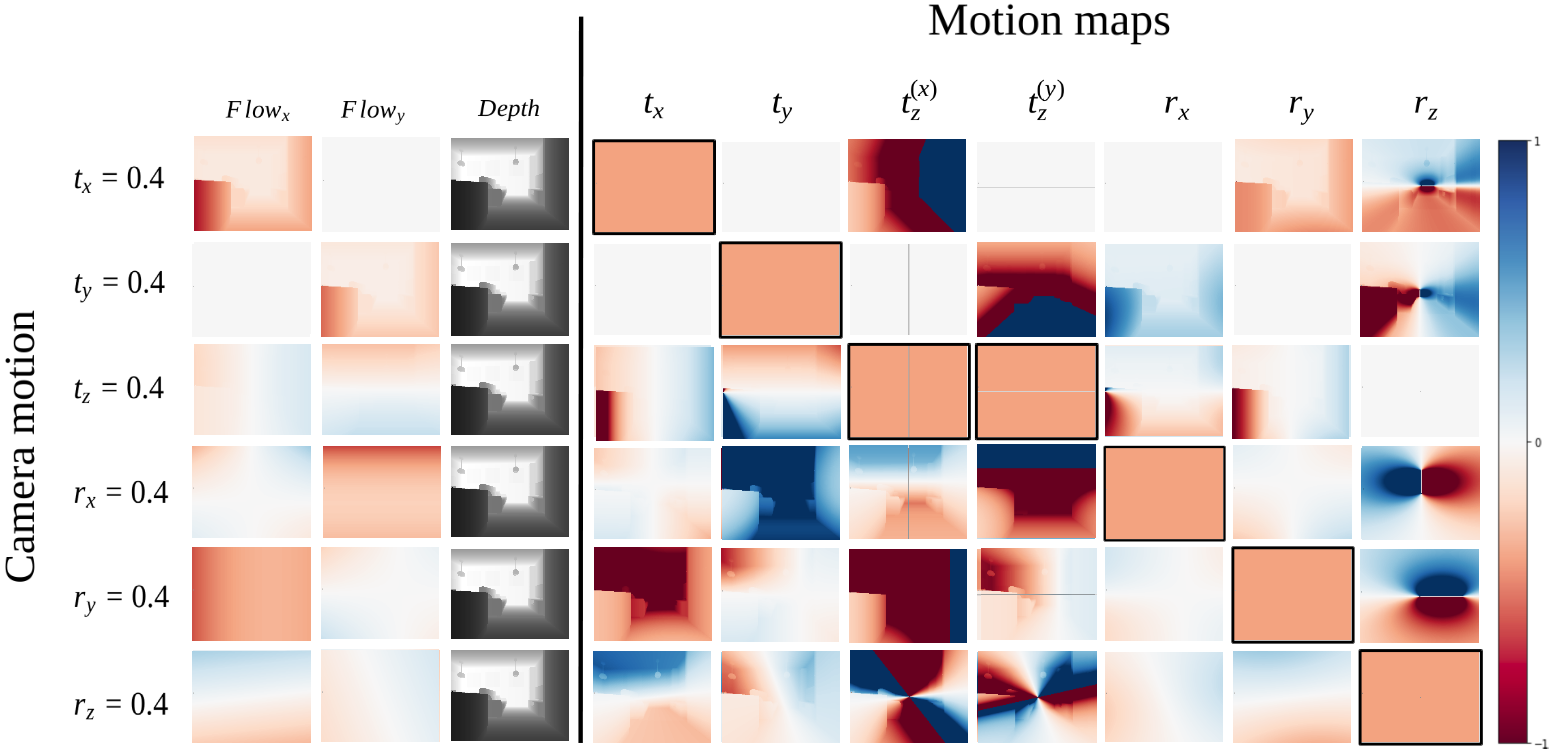
Developed state-of-the-art algorithms addressing 2D and 3D computer vision tasks: SLAM,
visual and sensor-based localization, 3D reconstruction of indoor scenes, depth estimation,
object segmentation, 2D and 3D object detection.
Formulated scientific hypotheses and conducted experiments to prove them. Wrote a number
of academic papers accepted to top-tier CV and robotics conferences such as CVPR, ECCV,
WACV, IROS. Overall, contributed to 16 papers. Outstanding Reviewer at NeurIPS 2022
Datasets and Benchmarks track. Own international patents on technical inventions.
Developed demos and PoCs on visual odometry, visual indoor navigation,
fruit and vegetable weight measurement based on RGB-D data. Collected, labeled
and prepared data for prototyping and research purposes: visual navigation,
3D reconstruction of indoor scenes, visual analytics for retail.
Mastered all kinds of writing: academic manuscripts, annual reports, patents, tasks
for data annotators, documentation, and internal guides.
Rambler&Co
Research Intern / Junior Data Scientist, Computer Vision
Contributed to a project on cinema visitor monitoring based on video surveillance data.
Developed algorithms based on deep neural networks (segmentation, classification, detection,
tracking). Collected, labeled, and prepared training data. Conducted experiments and
presented the results in the form of reports and slides.
What started as a small toy project run by one intern (me), was considered so successful
that it convinced top management to create a computer vision department, mostly to develop
and maintain the cinema monitoring system. The implemented solution was used to collect
statistics in over 700 cinema halls in Russia.